如何从PDF文件中提取原始图像
介绍
PDF 是最常用的文档类型之一。在某些情况下,您可能需要 PDF 文件中的图像,您可以对 PDF 文件进行屏幕截图以获取图像,但使用该方法获得的不是原始图像。更糟糕的是,当有大量图像时,它会花费你很多时间。本教程提供了从 PDF 文件中提取原始图像的完美解决方案. 无需安装任何软件 & 您无需担心文件的安全性受到威胁.
工具: 提取 PDF 图像. 现代浏览器,如 Chrome、Firefox、Safari、Edge 等。
浏览器兼容性
- 支持 FileReader、WebAssembly、HTML5、BLOB、Download 等的浏览器。
- 不要被这些要求吓倒,最近5年的大多数浏览器都是兼容的
操作步骤
- 首先打开您的网络浏览器,通过执行以下操作之一,您将看到浏览器如下图所示
- 选项 1: 输入以下内容 "https://zh-cn.pdf.worthsee.com/pdf-images" 显示为 #1 在下图中 或者;
- 选项 2: 输入以下内容 "https://zh-cn.pdf.worthsee.com", 然后打开 提取 PDF 图像 工具 通过导航 "PDF工具" => "提取 PDF 图像"
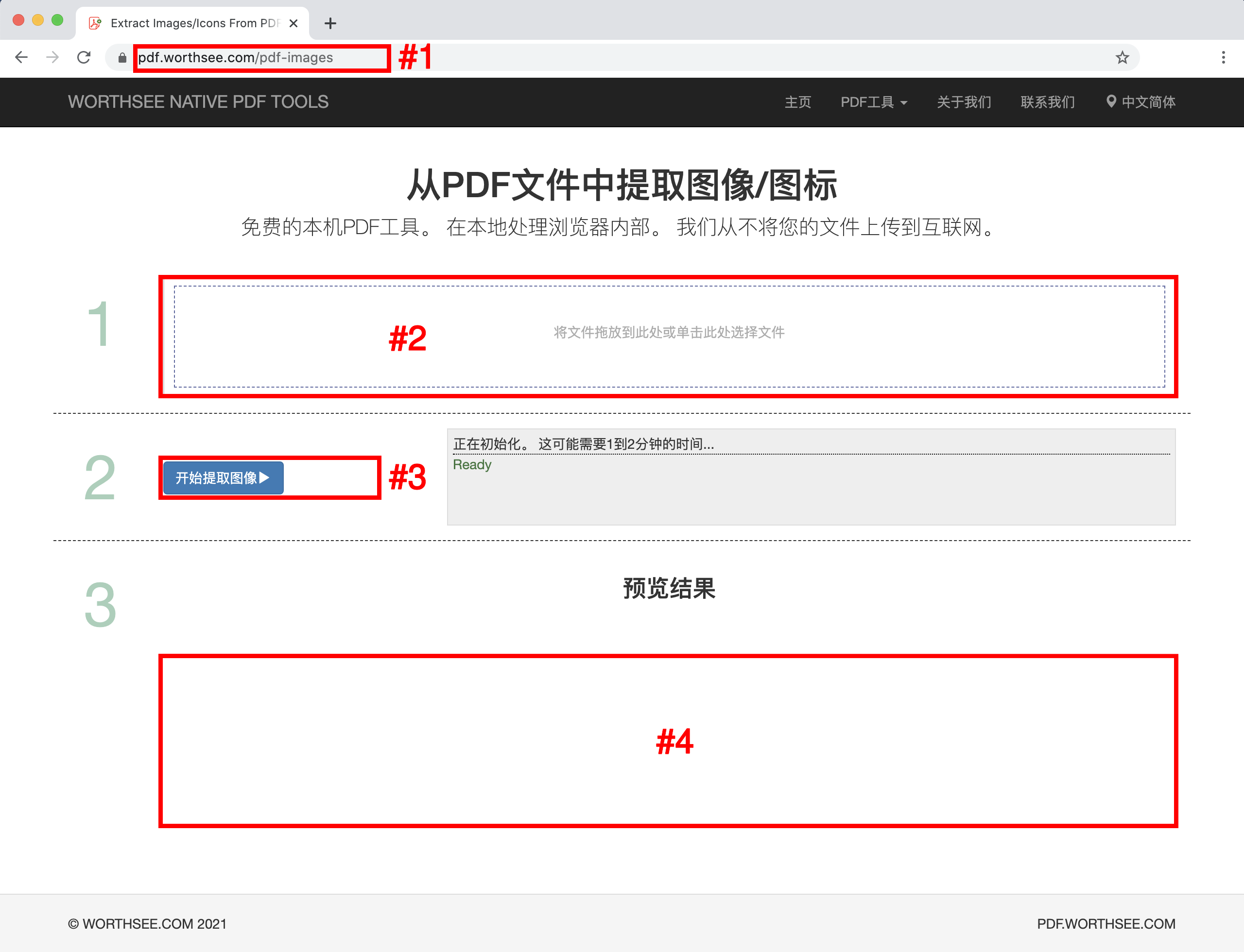
- 点击 区域 "将文件拖放到此处或单击此处选择文件" (显示为 区域 #2 在上图中) 选择PDF文件
- 您还可以将文件拖放到该区域
- 您可以根据需要选择任意数量的文件,也可以根据需要选择任意多次。
- 您选择的文件将显示在框下 #2 预览
- 点击 按钮 "开始提取图像" (显示为 按钮 #3 在上图中), 如果文件很大,可能需要一些时间
- 图像提取完成后,提取的图像文件将出现在图像所示的位置 #4 (如上图所示), 您只需单击它们即可下载
- 成功处理所选文件后将显示下载链接
- 我们还支持将生成的文件打包为 ZIP 文件。当生成的文件过多时,您可以使用此功能将它们打包成一个 zip 文件,这样您只需下载一次,而不需要多次点击下载所有文件